Struct And Union 内存分配
union 与 struct 内存分配
在Point Cloud Library(PCL)中自定义点(PointT)的类型时,为了利用SSE加速,需要满足特定内存对齐问题。在了解内存对齐之前,需了解对 struct 与 union 两种数据内存的分配问题。本文不讨论SSE加速以及内存对称问题,仅对 struct 与 union 两种数据以及两种数据类型的嵌套的内存分配问题做详细的分析。
union 内存分配
联合体,顾名思义,整个数据联合为一个整体,故其所有成员共享同一块内存区域。分配内存时,按照其数据成员中,占用内存最大的成员来分配最终内存大小。
union data{
int a; // int 占用内存最大的 4 byte
short b; // 2 byte
char c; // 1 byte
}
data 所占的空间等于其最大的成员所占的空间,即 int 为 4byte。对 union 型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始, 也就是联合体的访问不论对哪个变量的存取都是从 union 的首地址位置开始。成员 a, b, c 共享这 4byte 内存。其各成员所占用情况,如下图所示:
Address |
0x03 |
0x02 |
0x01 |
0x00 |
|---|---|---|---|---|
int a |
yes |
yes |
yes |
yes |
short b |
no |
no |
yes |
yes |
char c |
no |
no |
no |
yes |
而其各成员的值,因计算机存储模式有关。因此,大端(Big endian)和小端(Little endian)存储模式将会直接影响 union 内成员的值。
- 大端模式:字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中
- 小端模式:字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中
若令联合体成员 a = 4278190081 16进制表示为 0xff 00 00 01,
- 大端模式下,其内存中值的情况如下:
Address |
0x03 |
0x02 |
0x01 |
0x00 |
真实值 |
|---|---|---|---|---|---|
int a |
0x01 |
0x00 |
0x00 |
0xff |
0xff000001 |
short b |
no |
no |
yes |
yes |
0xff00 |
char c |
no |
no |
no |
yes |
0xff |
- 小端模式下,其内存中值的情况如下:
Address |
0x03 |
0x02 |
0x01 |
0x00 |
真实值 |
|---|---|---|---|---|---|
int a |
0xff |
0x00 |
0x00 |
0x01 |
0xff000001 |
short b |
no |
no |
yes |
yes |
0x0001 |
char c |
no |
no |
no |
yes |
0x01 |
由此可以看出,大端小端模式对联合体成员值的影响,反过来思考,则可以通过联合体成员值的不同,来判断存储模式为大端模式还是小端模式。
struct 内存分配
结构体是由一系列具有相同类型或不同类型的数据构成的数据集合,其各成员拥有各自独立的空间。其内存分配满足一下四个原则:
- 最大的基本类型为其成员以及其成员的成员中,所占内存最大的基本类型。该基本类型的大小作为结构体内存分配的最小单元\(w\)
- 内存的分配顺序与其成员的申明顺序相同
- 若成员为基本类型,则存放的起始地址相对于结构的起始地址的偏移量必须为该变量的类型所占用的字节数的倍数
- 若该成员不是基本类型,则存放在起始地址相对于结构的起始地址的偏移量必须为\(w\)的倍数。该成员内部成员独立遵循此四条原则
对于基本类型,CSDN解释如下:
- C++ 中的基础类型分为三个类别:整数、浮动和 void。 整数类型能够处理整数。 浮动类型能够指定具有小数部分的值。
个人认为基础类型应该包括指针类型。由上可知,数组、结构体以及类等并非基本类型,当其嵌入在结构体中是,应当注意其成员中的基本类型。
仅含有基本类型
struct data1{
int a;
char b;
short c;
};
struct data2{
char b;
int a;
short c;
};
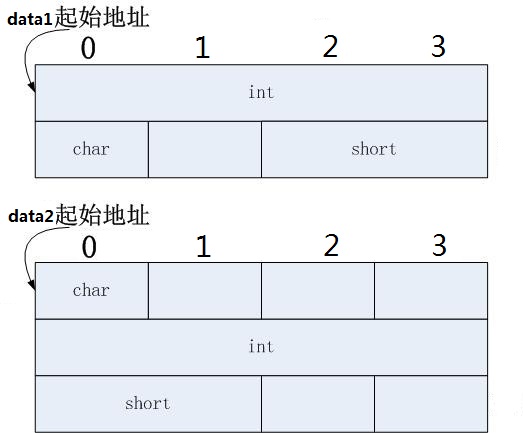
- 规则1:在
data1中,占内存最大的基本类型为int,故\(w=4\)。 - 规则2:先分配
int a,分配最小单元为\(w=4\) byte,a占用所分配的第0-3字节。再分配char b, 已无剩余空间,于是再分配最小单元数4byte。b占第4个字节。还剩第5-7字节 - 规则3:再分配
short c,地址偏移量需满足2的倍数,第5字节不满足,则b占用所分配的第 6、7个字节。
若将其成员申明顺序变换一下,如 data2,则按照上述原则,内存分配如下图所示。
含有非基本类型
struct data1{
int a; // 最大基本类型,则最小分配单元为4byte | 0 [a ][a ][ ][ ] 3
char b[5]; // 非基本类型,其成员类型为char,占1byte | 4 [b0][b1][b2][b3] 7
short c; // | 8 [b4][ ][c ][c ] 11
};
struct data2{
short s;
data1 d; // 非基本类型,data1成员中最大基本类型为 int, 则最小分配单元为4 byte
char c;
};
仍然按照上述四条原则来分析:
data1占12byte。data2中,data1子成员中最大基本类型为int,data2自身的基本类型成员最大为short,故最终最小分配单元为4byte,则先为s分配4byte,s占第0-1个字节。当分配data1 d时,根据第四条原则,第2-3字节不满足,d从第4个字节开始分配,其子成员在data1内部独立满足上述四条规则。占用第4-15个字节,共12byte,最终为char c分配4byte。data2共占20byte
用途
对于某些数据结构,使用 union 与 struct 嵌套,有利于其成员的访问。如下 pointXYZ 所示:
union pointXYZ{
float data[3];
struct{
float x;
float y;
float z;
};
};
当需使用 x, y, z 变量对其数据进行访问时,则提高代码可读性,某些情况下,对特定轴向进行数据分析时,使用 x, y, z 比 data[0], data[1], data[2] 更让人思路清晰。 当需要遍历点集中各个点数值等操作是,对其进行循环操作,则使用角标方式访问则更方便。 类似的有对于颜色的定义:
union colorRGBA{
uchar data[4];
struct{
uchar R;
uchar G;
uchar B;
uchar A;
};
int color;
};
整个结构 colorRGBA 仅占用 4byte, 可以在不同的场合使用不同的方式来访问其值。
blog comments powered by Disqus