Hacking Flappy Bird Using Q Learning Q-learning
Hacking Flappy Bird using Q-learning
flappy bird 正火的时候,已看到网络上有人写 flappy bird 的 AI ,如 Flappy Bird RL,用 js 实现的。 由于当时自己正在上机器学习的课程,且需要交小作业,觉得这个写 AI 是件很有趣的事,于是想动手实现这款游戏的 AI。
背景知识
监督式学习是对于任意的测试输入,希望学习机能够给予预期的输出。其对每个测试样本的决策往往独立。当需要对于序列的状态进行决策和控制,这使得监督学习很难找到一个明确的方式来监督学习。而增强学习则只需要提供一个 Reward function 来告之学习机当前的决策是好是坏。当学习机做出一个好的决策时,将被给予一个正的奖励,反正则给予负的奖励。关于增强学习的问题描述,可以通过马尔科夫决策过程(Markov Decision Processes, MDP)来进行描述。
马尔科夫决策过程
马尔科夫决策过程可以表示为一个5元组$(S,A,\{ P_{sa}\},\gamma,R)$,其中:
- $S$:状态(States)集合。例如 Flappy bird,其状态集合为 bird 状态集合,即 $\{position, lifeState \}$
- $A$:行动(Actions)集合。例如 Flappy bird,其行动集合为 $\{jump, nojump \}$
- $ P_{sa}$:状态转移概率分布。对于每一个状态 $s\in S$ 和每一个行动 $a\in A$,$P_{sa}$:状态空间中的一个概率分布函数。简单的说,即在状态$s$下执行行动$a$,$P_{sa}$ 决定要转移到的下一状态的概率分布。
- $\gamma\in[0,1)$:折现系数
- $R:S\times A\mapsto \Re$:Reward function,如果仅于状态有关,则为$R:S\mapsto \Re$
动态的 MDP 过程如下:从初始状态 $s_0$ 开始,选择行动$a_0 \in A$ 来进入 MDP。 MDP的状态根据$s_1 \sim P_{s_{0}a_{0}}$随机的转移至下一个状态$s_1$。然后又选择一行动 $a_2$,状态则根据$s_2 \sim P_{s_{1}a_{1}}$随机的转移至下一个状态$s_2$,依此继续。
$$
s_{0} \stackrel{a_{0}} {\rightarrow} s_{1} \stackrel{a_{1}} {\rightarrow} s_{2} \stackrel{a_{3}} {\rightarrow} s_{3} \cdots
$$
根据上述过程的状态序列 $s_{0},s_{1},s_{2},\cdots$ 和行动序列 $a_{0},a_{1},a_{2},\cdots$,得到最终的回报:
$$ R(s_{0},a_{0})+\gamma R(s_{1},a_{1})+ \gamma^2 R(s_{2},a_{2})+\cdots $$
对于 $\gamma$:若将 $R(\cdot)$ 理解为金钱,则 $\gamma$ 可以理解为利率,它使得今天的钱比明天的钱要值钱。促使学习机尽早的找到较好的回报,来使得最终的回报最大。
对于行动的选择,称之为 policy,其为一个从状态(States)集合到行动(Actions)集合的映射函数 $\pi:S\mapsto A$。当处于状态 $s$ 时,将执行行动 $a=\pi(s)$。增强学习的目的则是如何确定最优的 policy: $\pi^*$,来使得回报的期望最大。
$$ V^{\pi}(s)=E[R(s_{0},a_{0})+\gamma R(s_{1},a_{1})+ \gamma^{2} R(s_{2},a_{2})+\cdots|~~s_{0}=s,\pi] $$
$$ V^{*}(s)=\smash{\displaystyle\max_{\pi}} {V^\pi(s) = R(s)+\smash{\displaystyle\max_{a\in A}} \gamma \smash{\displaystyle\sum_{s^{'}\in S}} P_{sa}(s^{'})V^{*}(s^{'}) } $$
Value iteration 和 Policy iteration
当状态转移概率分布和 Reward function 已知时,对于有限状态的 MDP 的两种算法如下:
Value iteration:
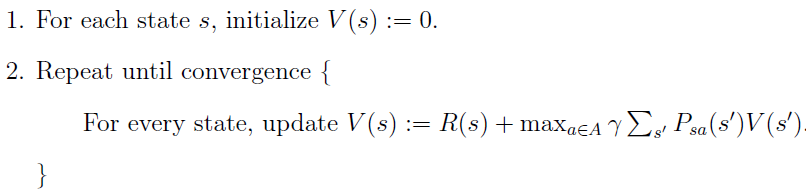
Policy iteration:

Q-learning
Q-learning 主要应用于拥有随机的状态转移的相关应用。其状态转移函数完全未知或无法估计,则无法对于奖励无法求取期望。其定义了一个 action-value function:$Q:S\times A\mapsto \Re$ 来衡量在状态 $s$ 下执行行动 $a$ 的质量。在状态 $s$ 下,选择使得 $Q(s,a)$ 最大的行动 $a$,来确定的最优 policy: $\pi$。 其求解过程是 Value iteration 的一个变种,$Q(s,a)$更新的公式如下:
$$ Q_{t+1}(s_{t},a_{t})=\underbrace{Q_{t}(s_{t},a_{t})}_{old~value}+ $$
$$ \underbrace{\alpha_{t}(s_{t},a_{t})}_{learning~rate} \times \left[ \overbrace{\underbrace{R_{t+1}}_{reward}+\underbrace{\gamma}_{discount~factor}\bullet \underbrace{\smash{\displaystyle\max_{a}}Q_{t}(s_{t+1},a)}_{estimate~of~optimal~future~value}}^{learned~value} - \underbrace{Q_{t}(s_{t},a_{t})}_{old~value} \right] $$
- $Q_{t}(s_{t},a_{t})$: 还未更新时的当前值
- $\alpha_{t}(s_{t},a_{t})\in (0,1]$:学习率
- $R_{t+1}$:在状态 $s_{t}$ 执行行动 $a_{t}$ 所获得的奖励,即$R_{t+1}=R(s_{t},a_{t})$
- $\smash{\displaystyle\max_{a}}Q_{t}(s_{t+1},a)$:到达状态 $s_{t+1}$ 以后,将选择能使 $Q_{t}(s_{t+1},a)$ 最大的行动 $a$ 作为下一步的行动。
其各参数对算法的影响可以参考 wiki of Q-learning
Hack flappy bird
Hack 的过程主要参考 FlappyBirdRL。我用C++实现了一个版本。主要在基于fancy2D游戏引擎开发的 C++ 版的 flappy bird做的改动,为了尽量不更改原作者的作品,本人仅在其代码中添加一个 pipe,将必要的状态数据传出来,以便训练。单独编写了一个 IA 程序,模拟鼠标点击来完成 AI 操作。
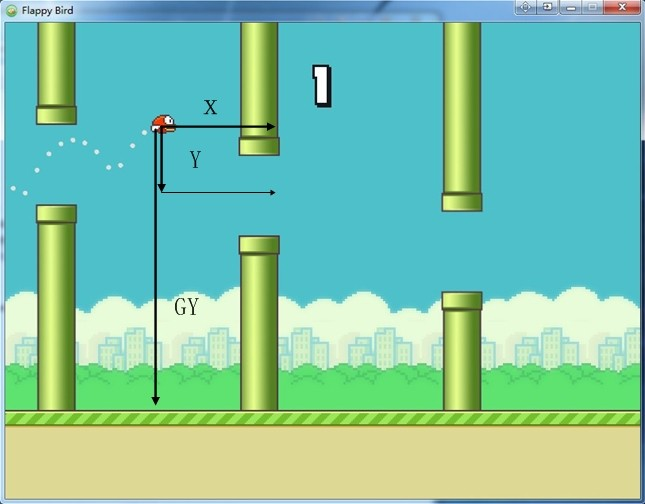
状态(States)集合 $S$:
X: 到下一管道右侧的水平距离
Y: 到管道间隙中心的垂直距离
GY: 到地面的垂直距离
Life: 活着,死亡
行动(Actions)集合 $A$:
Click: 跳
No Click: 不跳
Reward function $R(s,a)$:
+1: 当 Life = 活着
-1000: 当 Life = 死亡
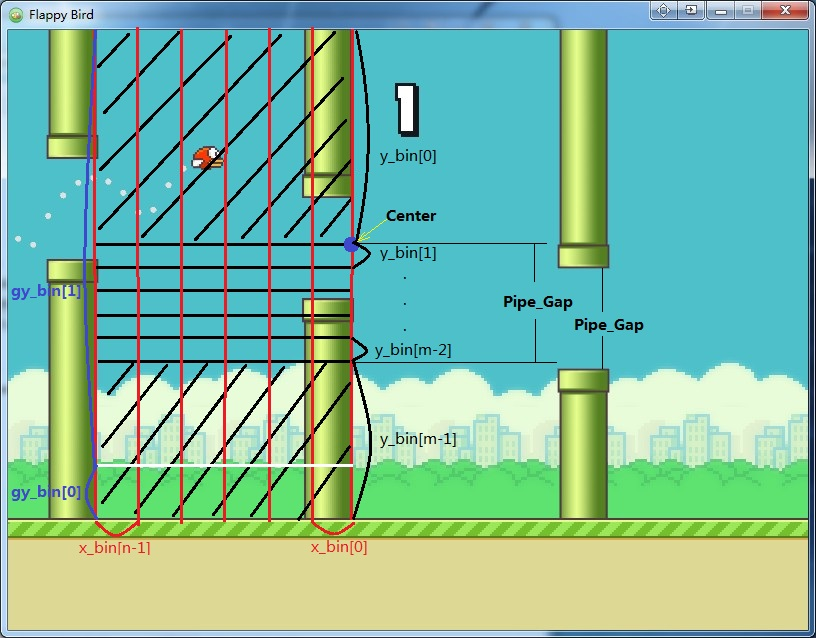
将状态空间离散化为有限的状态空间,为了加速收敛,可以人为加入一些先验知识。bird位于管道间隔中心上方时,始终选择 No Click,当靠近地面时或低于管道间隔中心一定范围时,始终选择 Click。状态空间划分$n\times m \times 2$,如图所示:
训练结果
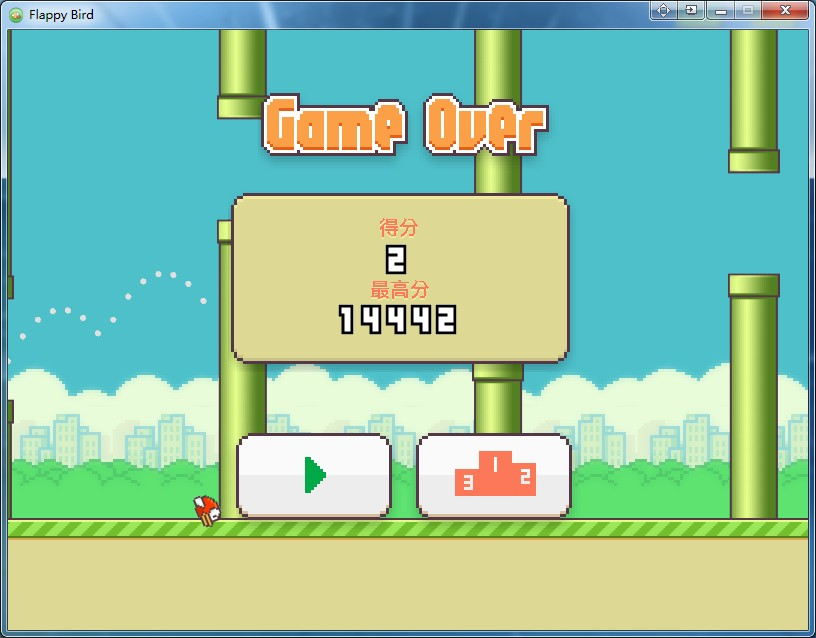
训练了一晚上,早上来实验室一看,最高分已经达到14442分了。
关于源码
blog comments powered by Disqus